Research Statement
(Last updated July 18, 2022)
Over time, human knowledge has mostly been expressed in text, some of which are unstructured. To make sense of these knowledge and understand the nuances of human language, computers have to be able to extract structured knowledge from unstructured text. In certain languages, semantically similar sentences could be worded differently and words are sometimes ambiguous, hence the specific sense of a word intended in a sentence is determined by the context in which an instance of the ambiguous word appears. Additionally, due to the lack of uniformity in individual writing styles, multiple people can express the same word, phrase, or sentence differently(e.g. a sports team could be referred to by its official name, the name of the city it plays in, or by any of several nicknames). These make it challenging to find similar words, phrases, and sentences that express the same information, in text.
My research interest focuses on applying machine learning to better understand the various ways in which words, phrases, and sentences are expressed. Currently, I have two main areas of research: Question Answering and Paraphrase detection.
Community Question Answering Systems
Community question answering (CQA) systems are online forums where users can ask and answer questions in various categories. A common challenge with these systems is that a significant percentage of asked questions are left unanswered, partly because: (I) they are short and lack relevant content, (II) they are not clearly expressed, and (III) they are not appropriately assigned to a user that is able to answer the question. In my research, my collaborators and I proposed the idea of using entity-based algorithms to reduce the number of unanswered questions in entity-rich question categories (e.g. Sports and Entertainment) of CQA’s by using past resolved questions (PARQ) from the site. In these entity-rich question categories, the vocabulary in questions can be diverse, and questions are often very short. We created a new dataset constructed from Yahoo! Answers. The dataset contains annotated question pairs, (given question, PARQ, and its corresponding answer) from the Sports and Entertainment question categories. We show that in question categories with lots of entities and entity variations, using entities, disambiguated entities, and extracting KB information associated with these entities will find most of the PARQ with shared needs or similar needs as given questions. Table 1 presents some of the named entities and their variations in our dataset.
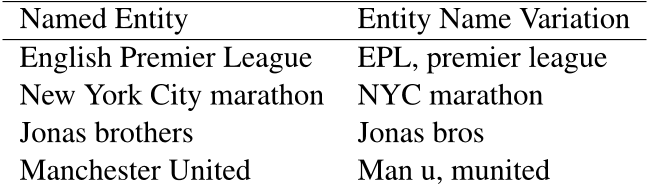
Table 1: Some named entities and their variations in our dataset.
Paraphrase detection
In certain fields, real-time knowledge from events can help in making informed decisions. In order to extract pertinent realtime knowledge related to an event, it is important to identify the named entities and their corresponding aliases related to the event. The problem of identifying aliases of named entities that spike has remained unexplored. In this paper, we introduce an algorithm, EntitySpike, that identifies entities that spike in popularity in tweets from a given time period, and constructs an alias list for these spiked entities. EntitySpike uses a temporal heuristic to identify named entities with similar context that occur in the same time period (within minutes) during an event. Each entity is encoded as a vector using this temporal heuristic.We show how these entityvectors can be used to create a named entity alias list. We evaluated our algorithm on a dataset of temporally ordered tweets from a single event, the 2013 Grammy Awards show. We carried out various experiments on tweets that were published in the same time period and show that our algorithm identifies most entity name aliases and outperforms a competitive baseline.
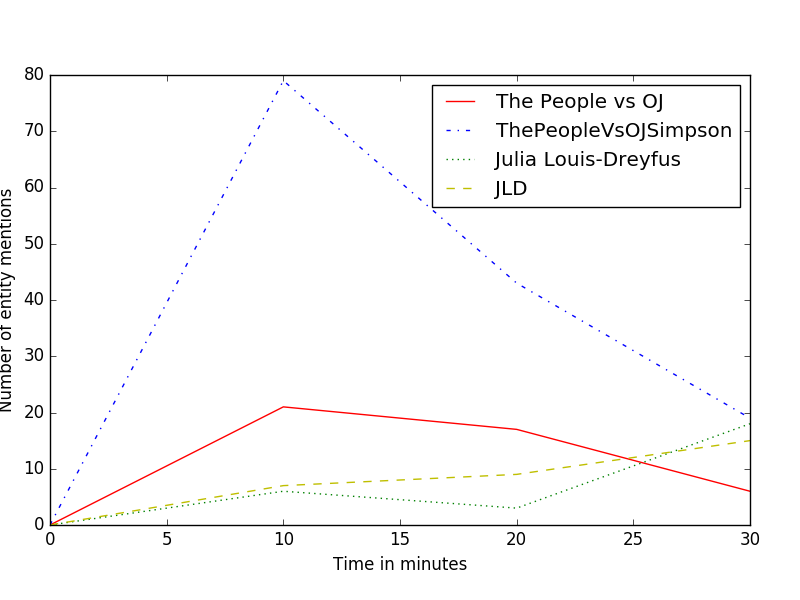
Table 1: Name variations of entities that spike in popularity at the same time in 10 minute bins during the 2016 Emmy awards show.